User Guide
本書はKAMONOHASHIを利用したAI開発をスムーズに行う為に各機能や手順を説明する事を目的としています。
前提
読者がLinux、Git、Dockerの基本的な知識を持つことを前提としています。
- Dockerが初めての方はリンク先を選択してください。以下のリソースは、Dockerについて学ぶのに役立ちます。
- Dockerとはなにかlaunch
- コンテナとはなにかlaunch
- Docker公式チュートリアルlaunch
概要
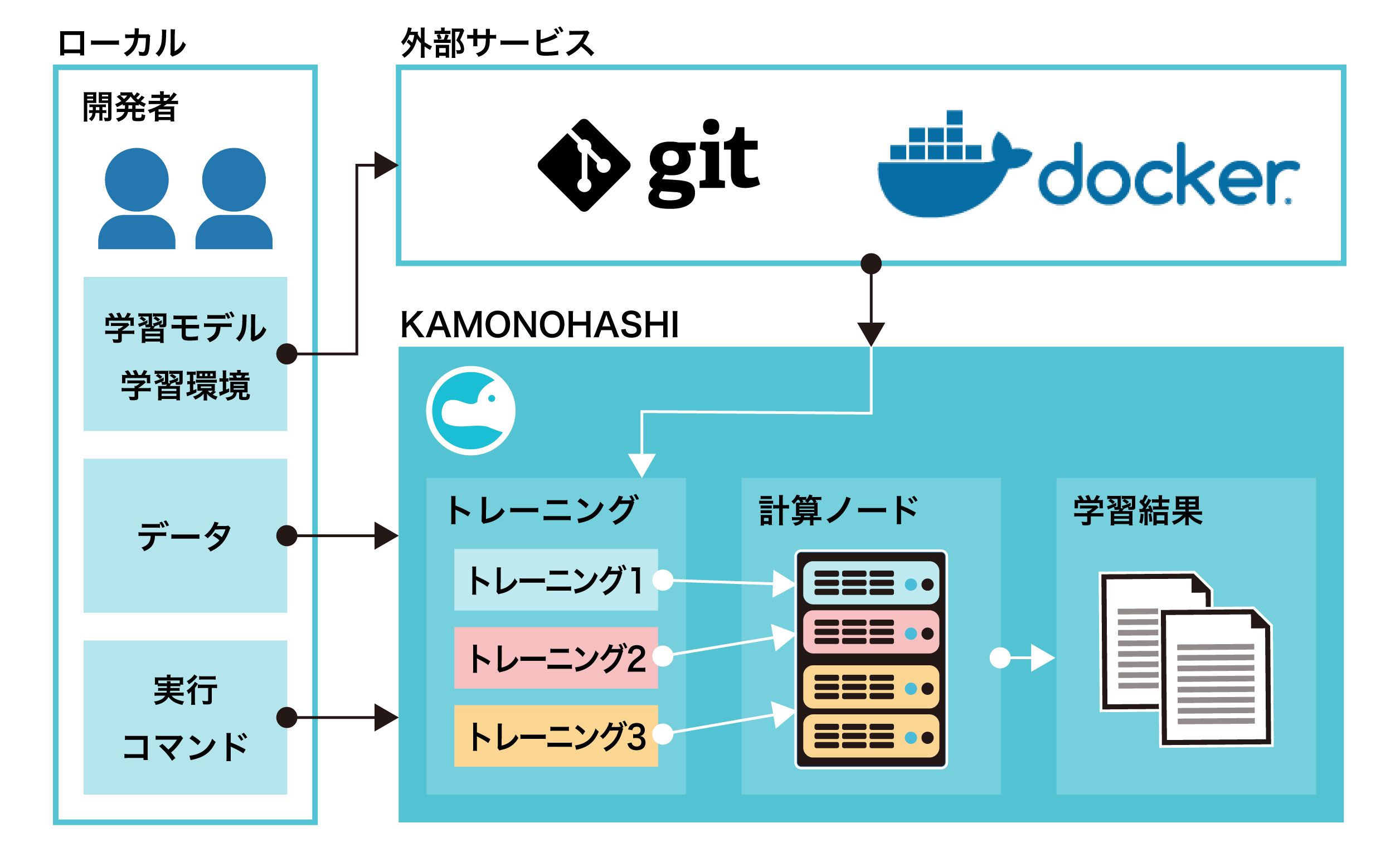
KAMONOHASHIの利用者は以下の操作を行えます。
KAMONOHASHIの利用者の想定操作は以下です。
ログイン
KAMONOHASHIはブラウザ・SDK・コマンドラインツールから使用できます。 ブラウザで開始するには、KAMONOHASHIにログインします。 KAMONOHASHIのURLが分からない場合はシステム管理者に問い合わせてください。
ログイン
KAMONOHASHIにログインするにはログイン画面からユーザ名・パスワードを入力します。 ユーザ名・パスワードはシステム管理者から提供されます。
テナントについて
テナントはKAMONOHASHIの最小の利用単位です。 テナント毎にリソースの使用量などが決められています。 ユーザは複数のテナントに所属することができます。
利用するテナントを切り替えるには、右上のユーザ名が表示されているリンクを押し、切り替えたいテナントを選択します。
ユーザ情報設定
利用者は右上のプルダウンメニューより[ユーザ情報設定]を選択することで、各種ユーザ設定情報の確認・変更が行えます。
Gitトークンの設定
KAMONOHASHIでは学習に用いる学習スクリプトなどを、システム管理者によって設定されたGitリポジトリサービスから取得します。
Gitリポジトリサービスへのアクセスに認証が必要な場合、ユーザ情報設定画面にて [Git Token]タブを選択し、認証情報を設定します。
レジストリトークンの設定
KAMONOHASHIでは、学習環境としてDockerコンテナを使用します。 このコンテナはシステム管理者によって設定されたDockerレジストリサービスから取得します。
Dockerレジストリサービスへのアクセスに認証が必要な場合、ユーザ情報設定画面にて [Registry Token]タブを選択し、認証情報を設定します。
Webhookの設定
-
KAMONOHASHI では学習・推論の実行成否を外部サービスである Slack にメッセージを通知することができます。
- ユーザ情報設定画面にて [Webhook]タブを選択し、通知先情報を設定します。
- 通知先URL には、事前に Slack API で作成した Webhook URL を入力します。
- 詳しくはSlack APIのドキュメントを参照してください。
- メンションには、通知したい Slack ユーザのユーザIDを入力します。
- 通知先URL には、事前に Slack API で作成した Webhook URL を入力します。
- 設定が完了し、学習または推論の実行完了した時、通知処理が実行されます。
- ただし、以下の理由により通知処理に失敗し通知されない場合があるため、設定時テスト通知を行うことを推奨します。
- 通知先URL の作成に失敗または入力内容に誤りがある。
- KAMONOHASHI のデプロイ時の設定に誤りまたは不足がある。
- ただし、以下の理由により通知処理に失敗し通知されない場合があるため、設定時テスト通知を行うことを推奨します。
テスト通知
- 入力された通知先URL 宛てにテスト通知を送ることができます。
- もし通知に失敗した場合
- 通知先URL の作成に失敗または入力内容に誤りがある可能性があります。
- KAMONOHASHI のデプロイ時の設定ファイルに
WebEndPointプロパティが設定されていない場合は通知をすることができないため、カスタマイズ設定ガイドを参照して設定してください。
データ管理
KAMONOHASHIでは Deep Learning等に利用するデータを管理することができます。データは画像やzipファイルなど、データ形式を問わず登録できます。
データを登録するには、[データ管理]を選択し、新規登録ボタンから行います。
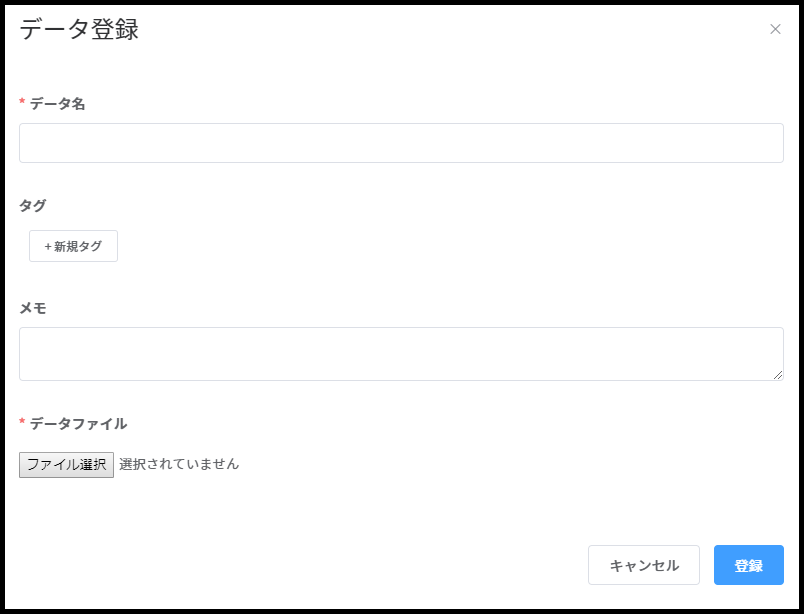
| 種類 | 説明 |
|---|---|
| データ名 | データの名前。 |
| メモ | 画像の説明など補足情報。 |
| タグ | データの種類や受領日などグルーピングしたい単位に付与し、検索等で利用する。 |
| ファイル | 複数のデータを登録できる。jpg/png/csv/zipなど、ファイルのデータ形式は任意。 |
前処理管理
前処理とは、既存データを元に、より目的に適した新しいデータを新規生成する処理のことです。例えば画像のトリミング処理などがこれにあたります。 KAMONOHASHIでは、データに対する前処理の実行、およびその履歴の管理を行うことができます。
ワークフロー
KAMONOHASHIで前処理を扱う場合、以下の二つのワークフローがあります。
- KAMONOHASHI管理の計算ノード上で前処理を実行する場合
- 全てのフローをKAMONOHASHIの管理範囲内で行う場合、前処理実行の自動化や並列処理、処理履歴のトラッキングを完全に行うことができます。
- フロー
- KAMONOHASHI上での前処理作成
- 前処理用ソースコードやコンテナなど、実行するための全情報の登録が必要となります。
- 登録した前処理の実行
- 登録済みのデータに対し、KAMONOHASHIの管理リソース上で前処理を実行します。
- 結果や履歴情報は全て自動で記録されます。
- KAMONOHASHI上での前処理作成
- KAMONOHASHI環境外で前処理を実施し、結果だけをKAMONOHASHIに登録する場合
- 前処理の実行自体は、ローカル環境などKAMONOHASHIの外で行い、結果だけをKAMONOHASHIにアップロードします。アップロード時の内容に従い、部分的に履歴管理が可能となります。前処理がKAMONOHASHIの管理リソース上で行えない場合(WindowsやMacOSが必要な場合など)に利用します。
- この操作は KAMONOHASHI CLI によってのみ実行が可能であり、WebUI上では行えません。
- フロー
- KAMONOHASHI上での前処理作成
- 必須入力は前処理名のみ。その他情報は任意で設定する。
- KAMONOHASHI外での前処理実行
- ローカル環境などで前処理を行う。
- 結果と履歴情報の保存
- 前処理結果ファイルと、その履歴情報(対象データや試用した前処理など)を登録する。
- KAMONOHASHI上での前処理作成
前処理の管理と作成
KAMONOHASHIで前処理を管理するためには、まず前処理の登録を行います。実行前に前処理を登録しておくことで、その前処理を多数のデータに任意のタイミングで適用することができます。
前処理を登録するには、[前処理管理]を選択し、右上の新規登録ボタンから行います。
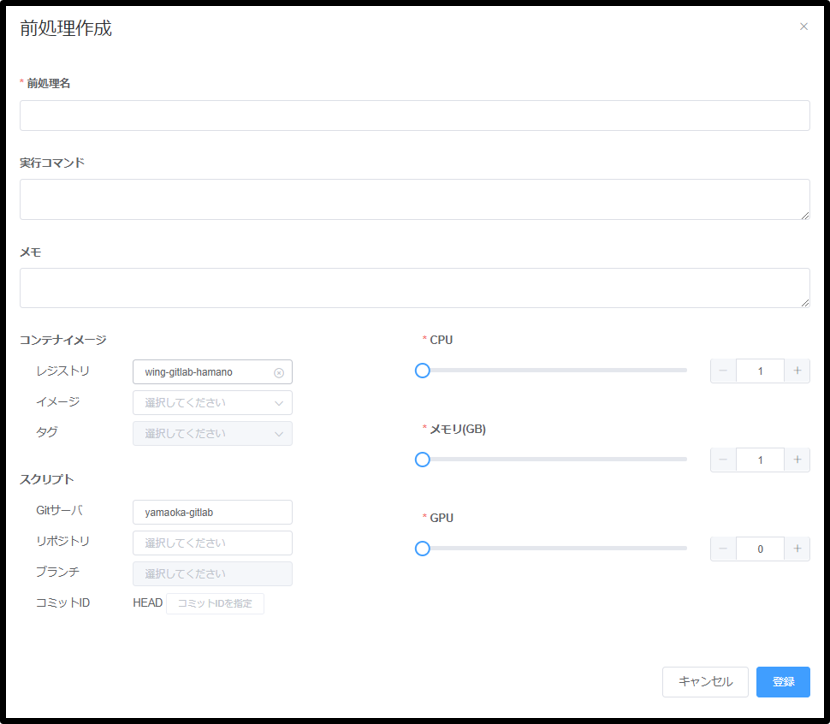
| 種類 | 要否 | 説明 |
|---|---|---|
| 前処理名 | 必須 | 前処理の名前。任意の文字列を指定可能。 |
| 実行コマンド | 任意 | 前処理として実行するコマンドを指定する。コンテナイメージに設定されたcommand, entrypointは無効になり、このコマンドのみが実行される |
| メモ | 任意 | 前処理に付与する任意のメモ。 |
| コンテナイメージ | 任意 | 利用するDockerレジストリ、コンテナ、タグを指定する。 |
| モデル | 任意 | ソースコードを格納しているGitサーバ、リポジトリ、ブランチ、コミットIDを指定する。コミットIDを指定した場合はブランチの入力値は無視される。コミットIDが未指定の場合はブランチのHEADが選択される。 |
| CPU | 任意 | 前処理が使用するCPUコア数のデフォルト値を指定する。実行時に再設定が可能。 |
| メモリ | 任意 | 学習が使用するメモリ量(GB)のデフォルト値を指定する。実行時に再設定が可能。 |
| GPU | 任意 | 学習が使用するGPU枚数のデフォルト値を指定する。実行時に再設定が可能。 |
KAMONOHASHI上で前処理を実行したい場合は、メモを除くすべての項目が必須入力となります。
前処理実行
KAMONOHASHIで前処理を実行するためは、以下3つのフローのいずれかで前処理実行画面を表示します。
- 前処理管理画面から前処理を行う場合
- 前処理管理画面を表示する
- 右上の[前処理実行]ボタンを押す
- 登録済みのデータ、リソースを設定し実行する
- データ管理画面から1つのデータに前処理を行う場合
- データ管理画面を表示する
- 前処理の対象データを選択し、データ編集画面を表示する
- 右上の[前処理実行]ボタンを押す
- 登録済みの前処理を選択、リソースを設定し実行する
- データ管理画面から複数のデータに前処理を行う場合
- データ管理画面を表示する
- 全ての前処理の対象データに対し、データIDの左側に表示されたチェックボックスを選択する
- データ管理画面右上の[前処理実行]ボタンを押す
- 登録済みの前処理を選択、リソースを設定し実行する
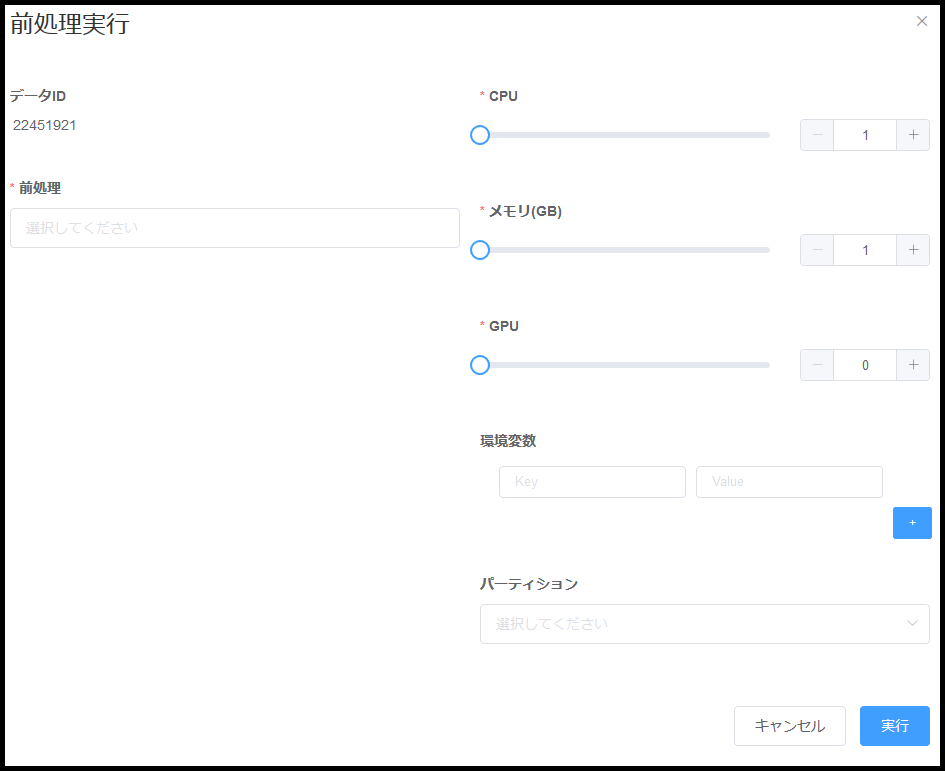
| 種類 | 要否 | 説明 |
|---|---|---|
| 前処理 | 必須 | 実行する前処理を選択する。 |
| 環境変数 | 任意 | 前処理に渡す環境変数を指定する。環境変数はコンテナ内の環境変数へ追加設定される。 |
| パーティション | 任意 | KAMONOHASHI に設定されているパーティションを設定する。例えばGPUの型番などはここから指定する。 |
| CPU | 必須 | 使用するCPUコア数を指定する。 |
| メモリ | 必須 | 使用するメモリ量(GB)を指定する。 |
| GPU | 必須 | 使用するGPU枚数を指定する。 |
| 実行後に履歴を開く | 任意 | ONにした場合、[実行]ボタンの押下後に当該前処理の履歴画面へ遷移する。OFFの場合は前の画面に戻る。 |
前処理実行の仕様
KAMONOHASHIによる前処理の実行フロー
前処理の実行フローは以下のようになっています。
- クラスタからリソースを確保する
- リソースに十分な空きがなかった場合は待機します。
- リソース上にコンテナがデプロイされる
- コンテナ内に環境変数が設定されます。
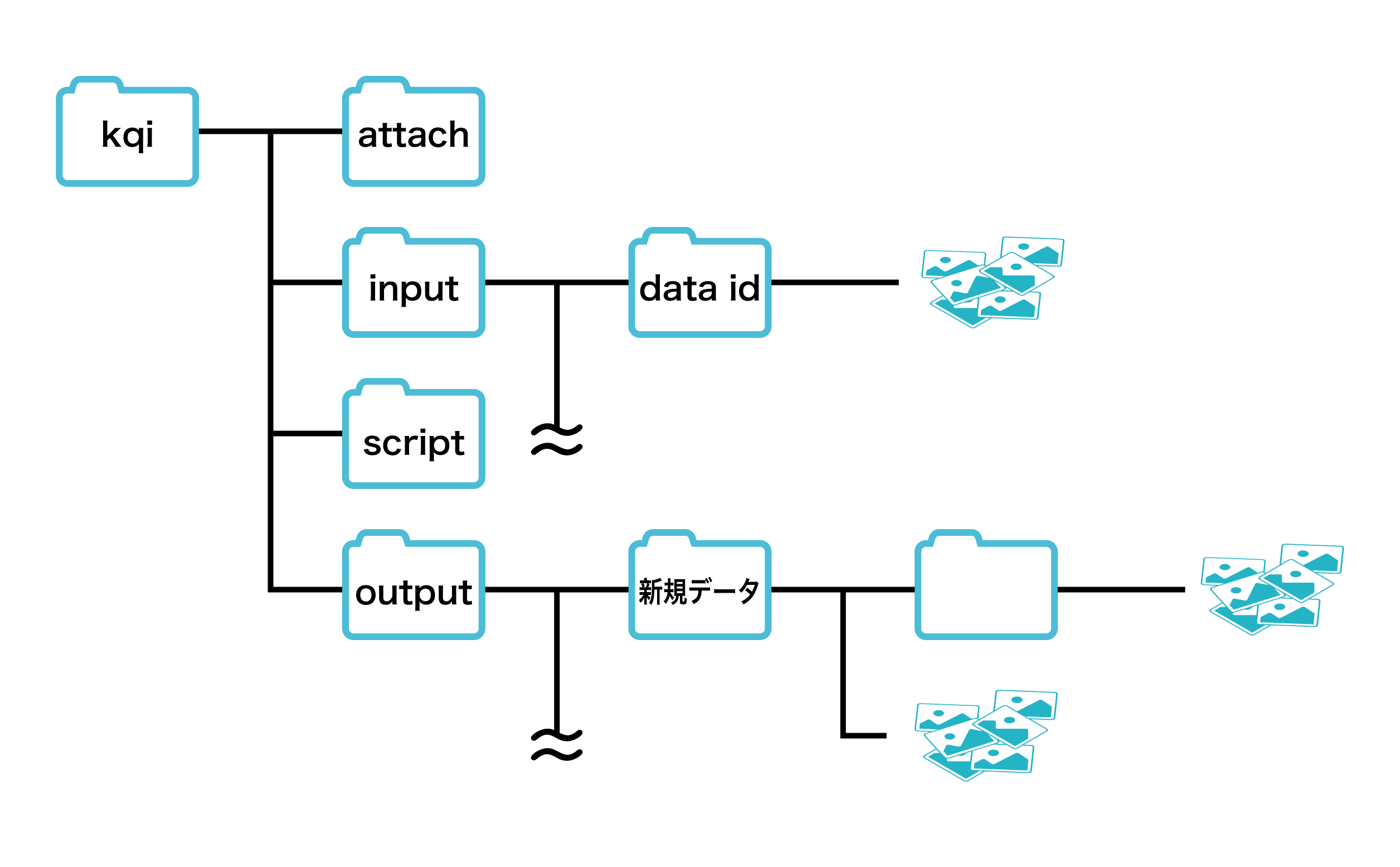
- 学習結果ファイル保存用ディレクトリ /kqi/output を作成する
- KAMONOHASHI の学習制御に必要なツールをインストールする
- git, python, pip, kamonohashi-cli がコンテナにインストールされます
- コンテナに既にこれらのツールがインストール済みだった場合はスキップされます
- 前処理スクリプトを /kqi/git/ に git clone する
- データセットを /kqi/input/{データID}/データファイル にダウンロードする
- 指定された「実行コマンド」が実行される
- /kqi/git/ がカレントディレクトリになります
- 実行ユーザはコンテナのrootユーザとなります
- 学習中、結果ファイルが /kqi/output/{前処理後結果として作成されるデータの名前}/ に書き出されるように「実行コマンド」または前処理スクリプトの記述が必要です
- /kqi/output/{前処理後結果として作成されるデータの名前}/ 以下のファイルは全て新規データに追加される。サブディレクトリ内のファイルも再帰的に新規データに追加されます。
- /kqi/output/ 直下のファイルは新規データに追加されません。
- 出力ファイルはzip圧縮されません。
- 結果のリアルタイム確認はできません。
- 実行ログを確認する
- 前処理履歴編集画面の閲覧ボタンを押下すると、実行ログがブラウザ上で確認できます。
- 前処理履歴編集画面の添付ファイル「stdout_stderr_.log」からダウンロードできます。
- 実行結果のステータスが更新される
- KAMONOHASHIの実行成否は、実行後の “$?” コマンドの結果で判断されます。
- そのため、実行コマンド自体は改行して複数記述可能ですが、結果の成否判定が難しくなるため、単一コマンドを推奨します。
- コンテナが停止し、リソースが開放される
フォルダ構造
注意事項
前処理は、同じデータに対して1度しか実行できません。 スクリプトのエラー等で再度実行したい場合、前処理履歴を削除する必要があります。削除時は生成された前処理結果データも同時に削除されるので注意が必要です。
データセット管理
データセットとは、データを Training/Validation/Test などのグループに分割し、機械学習などで処理するために利用します。
KAMONOHASHIでは後述する学習を実行する際の入力ファイルは、データセット単位となっています。
学習実行時に使用するデータセットを指定すると、training 等の分類に応じてコンテナの/kqi/input/<分類>/<データID>/<ファイル名>というパスにデータセットのファイルが配置されます。この分類は配置種別の設定でFlatを指定することで省略することもできます。その場合は/kqi/input/<データID>/<ファイル名>というパスで配置されます
KAMONOHASHIではトレーサビリティを重視しているため、一度学習と関連付けられたデータセットは変更できません。
データセットを作成するには、[データセット管理]を選択し、右上の新規登録ボタンから行います。
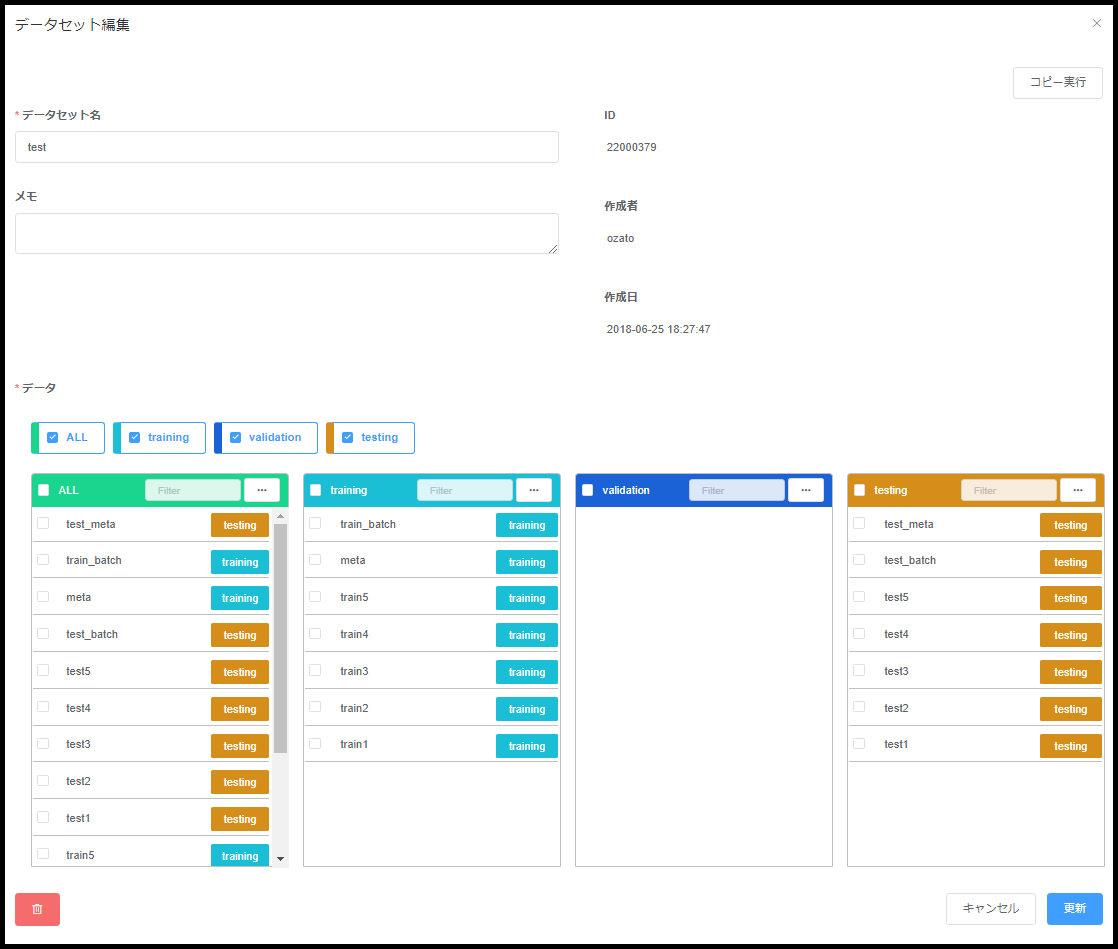
| 種類 | 説明 |
|---|---|
| データセット名 | データセットの名前。 |
| メモ | データセットを説明するメモ。 |
| 配置種別・フラット | オンにした場合、training等の組み分けを省略します。 |
| データ | allに表示されるデータ一覧からそれぞれのエリアにドラッグで移動させることでデータを分割していく。 |
データセットのコピー
KAMONOHASHI では1度学習に利用したデータセットは編集できなくなります。このため、過去に利用したデータセットから派生して処理を行いたい場合には、データセットをコピーして利用します。データセットをコピーするには、一覧からコピーしたいデータセットを選択し、右上のコピーボタンから行います。
学習管理
学習は KAMONOHASHI が管理するクラスタで計算を実行するための最小単位を表します。 学習を開始すると KAMONOHASHI はクラスタから指定されたCPU、メモリ、GPUリソースを確保し、Dockerコンテナを起動して計算環境を用意します。ユーザはこの環境を利用し、任意の計算を行うことができます。
学習の開始
学習を開始するには[学習管理]を選択し、右上の新規登録ボタンから行います。実行コマンドやモデルの仕様については後述。
学習の実行は4ステップにて行います。
ステップ1

| 種類 | 要否 | 説明 |
|---|---|---|
| 学習名 | 必須 | 学習の名前。 半角英数小文字、または記号(“-”(ハイフン)) 30 文字以下で指定可能。 |
| マウントする学習 | 任意 | 既に実行した学習との関連付ける場合に指定する。指定時に親学習の設定がコピーされるので、変更したい箇所を指定後に変更する。また、親に指定した学習の出力結果が、コンテナにマウントされる。 |
| データセット | 必須 | 学習の入力ファイルとなるデータセットを指定する。 |
| データセット作成方法 | 必須 | コンテナ内へのデータセットの作成方式を指定する。設定による動作の違いは、学習の実行フローの項目に記載。 |
ステップ2
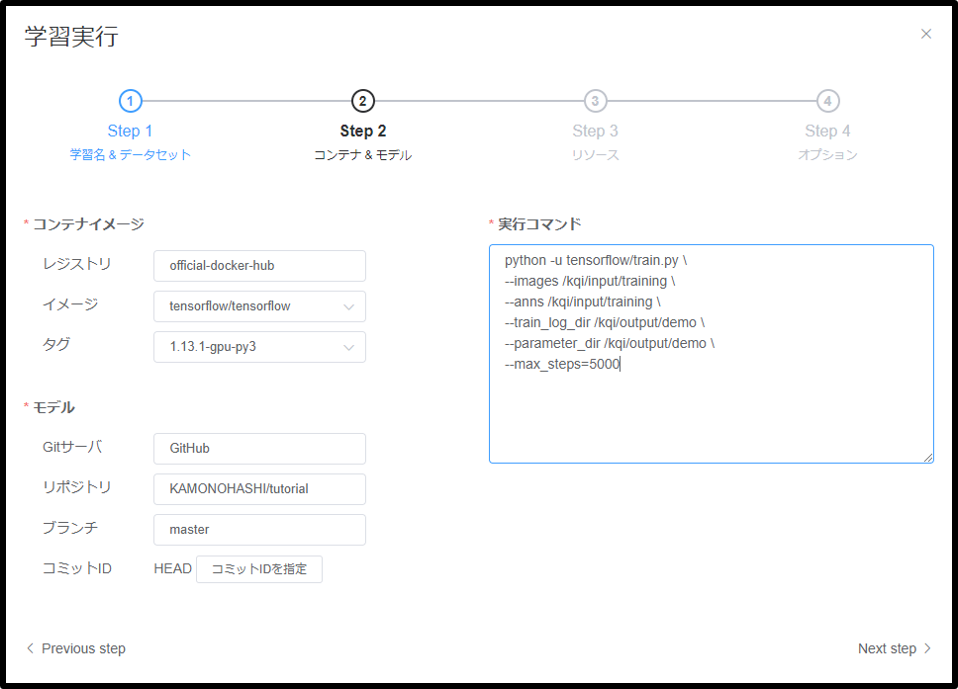
| 種類 | 要否 | 説明 |
|---|---|---|
| コンテナイメージ | 必須 | 利用するDockerレジストリ、コンテナ、タグを指定する。 |
| モデル | 必須 | ソースコードを格納しているGitサーバ、リポジトリ、ブランチ、コミットIDを指定する。コミットIDを指定した場合はブランチの入力値は無視される。コミットIDが未指定の場合はブランチのHEADが選択される。 |
| 実行コマンド | 必須 | 学習で実行するコマンドを指定する。コンテナイメージに設定されたcommand, entrypointは無効になり、このコマンドのみが実行される |
ステップ3
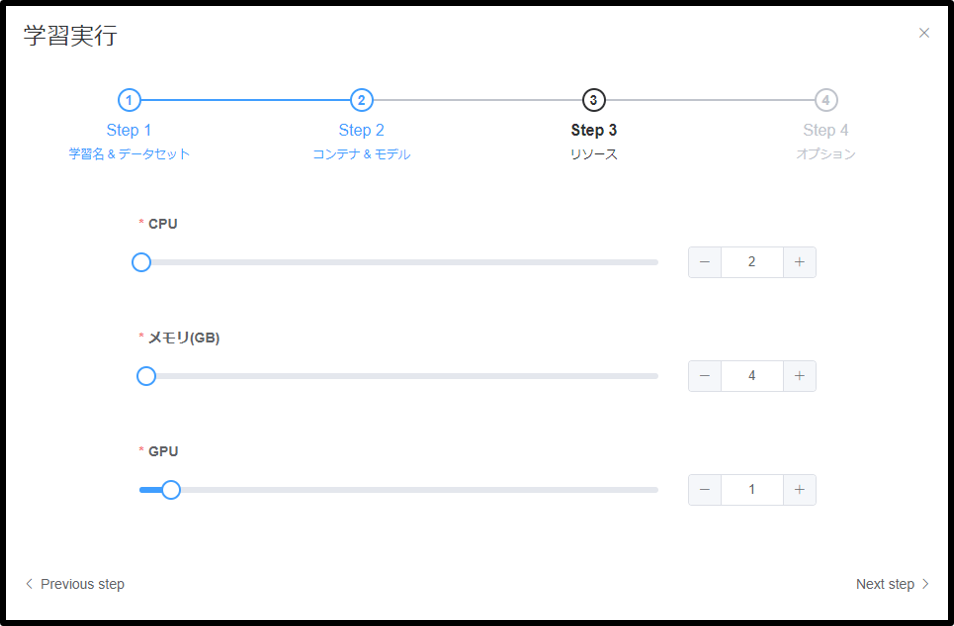
| 種類 | 要否 | 説明 |
|---|---|---|
| CPU | 必須 | 学習が利用するCPUコア数を指定する。 |
| メモリ | 必須 | 学習が利用するメモリ量(GB)を指定する。 |
| GPU | 必須 | 学習が利用するGPU枚数を指定する。 |
ステップ4
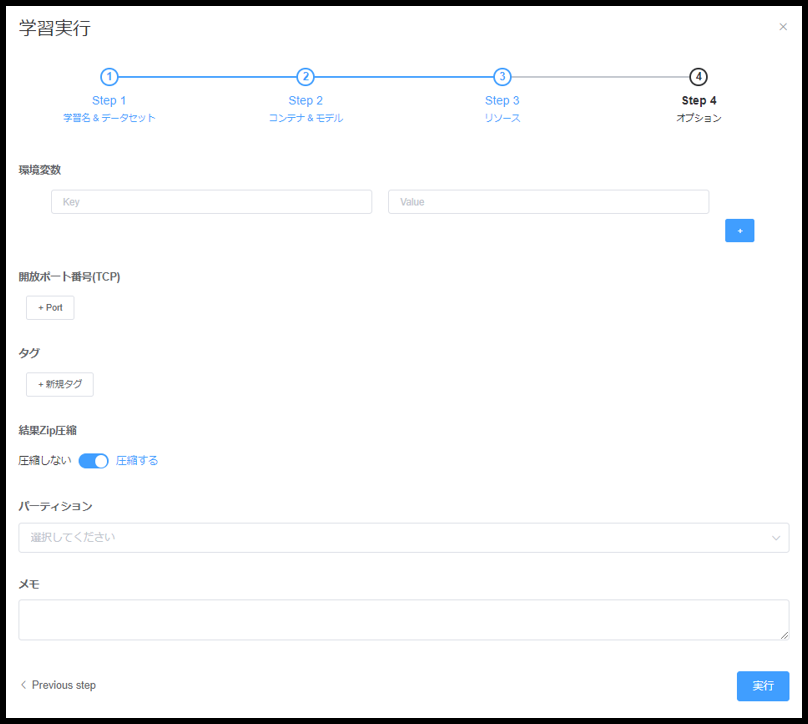
| 種類 | 要否 | 説明 |
|---|---|---|
| 環境変数 | 任意 | 学習に渡す環境変数を指定する。環境変数はコンテナ内の環境変数へ追加設定される。 |
| 開放ポート番号(TCP) | 任意 | コンテナで開放するポート番号を指定する。ここで指定したポートが開放され、学習実行中ノードポート経由でアクセスできる |
| タグ | 任意 | 学習に対してタグ付けを行い、検索等で利用する。 |
| 結果zip圧縮 | 必須 | 学習終了後の結果ファイルをzip圧縮するかどうかを指定する。 |
| パーティション | 任意 | KAMONOHASHI に設定されているパーティションを設定する。例えばGPUの型番などはここから指定する。 |
| メモ | 任意 | 学習に付与する任意のメモ。 |
学習の確認
過去に実行した学習の情報・状態・結果などを確認したい場合、[学習管理]の画面で該当学習を選択し、学習履歴画面を表示します。
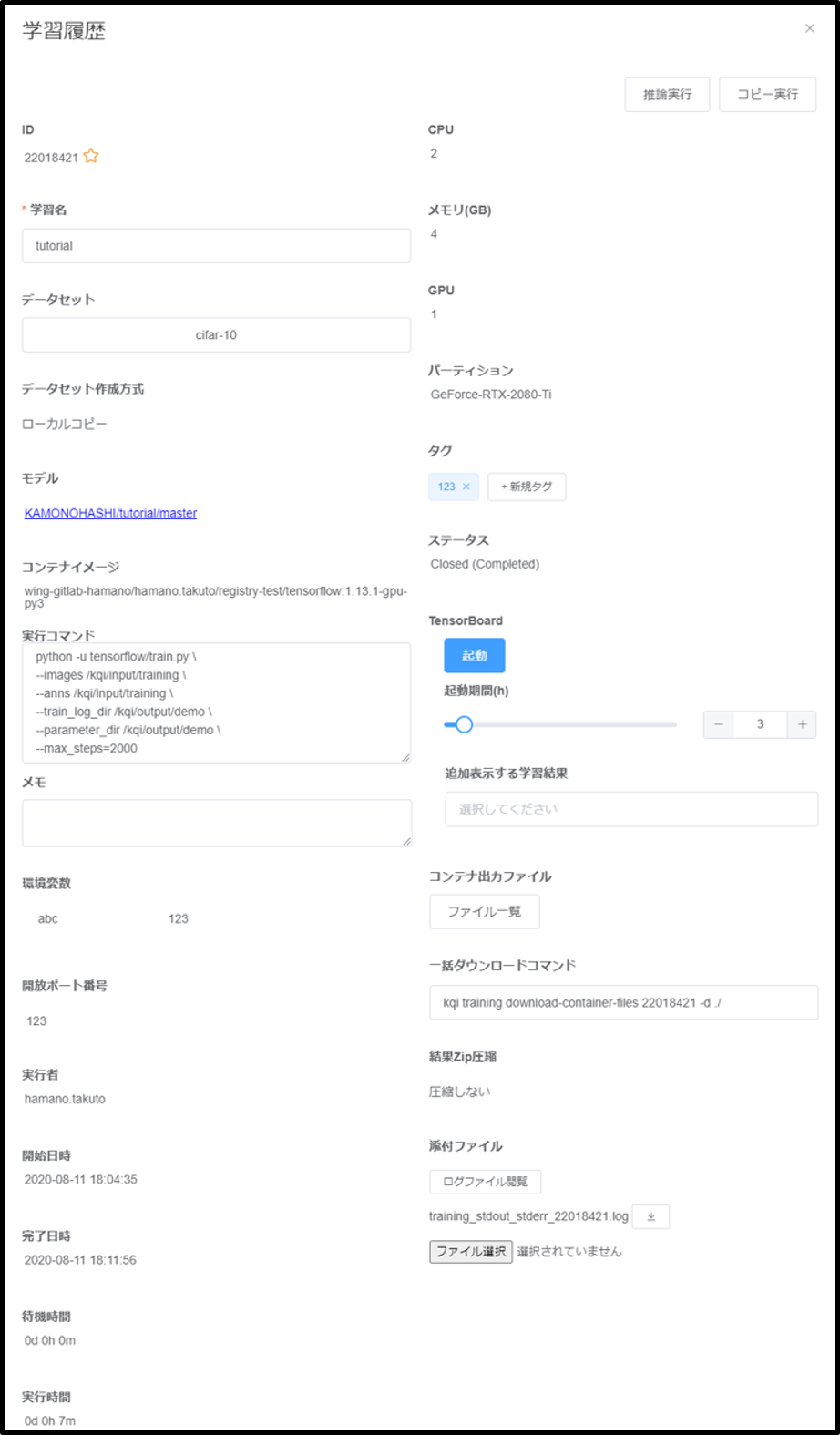
学習履歴画面では、各種情報が項目毎に一覧化されており、以下のことなどが行えます。
TensorBoard の起動
学習を実行しているコンテナの TensorBoard を表示したい場合、[学習管理]の画面で該当学習を選択します。 TensorBoardの項目から起動ボタンを押下することで、指定した期間の間Tensorboadが起動できます。 また追加表示する学習結果の項目に他の学習結果を指定することで、複数の学習結果をTensorboardで表示することができます。 ただしそれぞれの学習について、学習の結果ファイルとしてTensorBoardに読み込ませるログデータが出力されている必要があります。
学習の停止
学習を停止したい場合、[学習管理]の画面で該当学習を選択します。操作の項目にある学習停止ボタンから学習を停止することができます。 ※この操作は学習のステータスがRunning時のみ実行可能です。
シェル起動
学習を実行しているコンテナに接続したい場合、[学習管理]の画面で該当学習を選択し、[Shell起動]ボタンを押下します。 コンテナ内のrootユーザとしてシェルが立ち上がり、コンテナ内で任意のコマンドを実行できます。 ※この操作は学習のステータスがRunning時のみ実行可能です。
学習コンテナへのアクセス
コンテナアクセス欄に表示されているNode Portを介して、学習実行時に指定したTarget Portへアクセスできます。 ※この操作は学習のステータスがRunning時のみ実行可能です。
コピー実行
類似の学習を投入したい場合は、過去の該当学習を選択し右上のコピー実行ボタンから行えます。コピー実行を選択すると、 過去の学習を投入した情報が初期値として設定され、必要な個所を変更して実行できます。
学習の仕様
KAMONOHASHIによる学習の実行フロー
学習の実行フローは以下のようになっています。
- クラスタからリソースを確保する
- リソースに十分な空きがなかった場合は待機します。
- リソース上にコンテナがデプロイされる
- コンテナ内に環境変数が設定されます。
- 親学習の指定があった場合、/kqi/parent に親学習の出力結果を読み取り専用でマウントする
- テナントのデータを /kqi/raw にマウントする
- 学習結果ファイル保存用ディレクトリ /kqi/output を作成する
- KAMONOHASHI の学習制御に必要なツールをインストールする
- git, zip, python, pip, kamonohashi-cli がコンテナにインストールされます。
- コンテナに既にこれらのツールがインストール済みだった場合はスキップされます。
- モデルを /kqi/git/ に git clone する
- データセットを /kqi/input に作成する
- データセット作成方式でシンボリックリンクを選択した場合は、/kqi/data にマウントした各データに対するシンボリックリンクが作成されます。
- データセット作成方式でローカルコピーを選択した場合は、/kqi/data にマウントした各データのコピーが作成されます。
- ※データセットの作成時間はシンボリックリンク作成の方が短いですが、学習で頻繁にデータの読み込みが発生する場合はローカルコピーを用いた方が実行時間は短くなります。
- 指定された「実行コマンド」が実行される
- /kqi/git/ がカレントディレクトリになります。
- 実行ユーザはコンテナのrootユーザとなります。
- 学習中、結果ファイルが /kqi/output に書き出されるように「実行コマンド」またはモデルの記述が必要です。
- 結果ファイルを保存する
- zip圧縮を行う場合、/kqi/output をzip圧縮する。このファイルは学習履歴画面の添付ファイル「output.zip」からダウンロードできます。
- 実行結果のステータスが更新される
- KAMONOHASHIの実行成否は、実行後の “$?” コマンドの結果で判断されます。
- そのため、実行コマンド自体は改行して複数記述可能ですが、結果の成否判定が難しくなるため、単一コマンドを推奨します。
- e.g. 評価スクリプトを裏で実行するなど、複数操作が必要な場合は modelリポジトリにその処理を行うスクリプトを置きます。
- コンテナが停止し、リソースが開放される
フォルダ構造
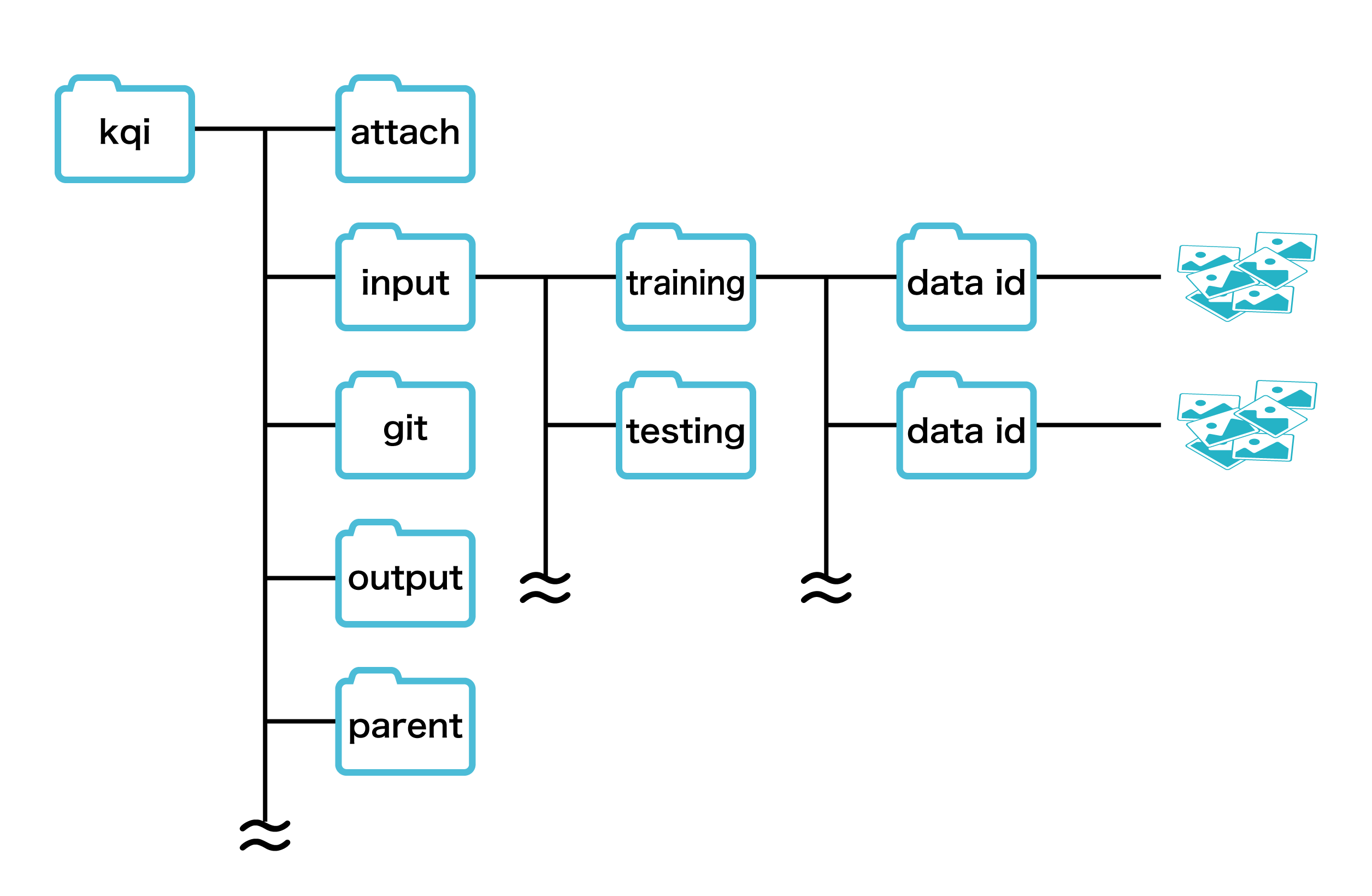
/kqi/input/ 入力ファイル
- 実行時に指定したデータセットは /kqi/input/ に指定した作成方式に応じて作成されます。
- ファイルは /kqi/input/{データ種別名}/{データID}/データファイル という構造で配備されます。
- データセットのFlatモードを選択した場合は/kqi/input/{データID}/データファイルというパスになります
/kqi/output/ 出力ファイル
- /kqi/outputに結果ファイルを書き出すようにします。
- /kqi/output/配下のファイル名・ディレクトリ名は次の文字だけ使用可能です。
- -_1-9a-zA-Z/
- /kqi/output に書き込まれたファイルは 学習履歴画面の「ファイル一覧」ボタンからリアルタイムに閲覧・ダウンロードできます。
- /kqi/output内のあるディレクトリにおけるファイル数とディレクトリ数の上限は10,000件となっています。この件数を超えて出力されたものは、ファイル一覧での閲覧およびCLIでのダウンロードが出来なくなるため注意してください。出力ファイル数が多い場合はディレクトリを作成して分散させるなどの対応をお願いします。
/kqi/git/ 学習モデル
- 実行時に指定したモデルは /kqi/git/ に git clone されます。
- モデルに限らず、コンテナ内で実行したいコマンドがあれば、スクリプトで記述してモデルと共にリポジトリに入れておきます。
- 実行時のカレントディレクトリはこの /kqi/git/ になります。
- 例:リポジトリのトップに「entrypoint.py」を置いた場合、 学習実行の「実行コマンド」には「python entrypoint.py」を記述します。
/kqi/attach 添付ファイル
- 学習履歴画面にて、添付ファイルとしてアップロードされたファイルが格納されます。
/kqi/parent 親学習の結果ファイル
- 親学習を指定した場合、指定した学習の出力結果(当該学習の /kqi/output に出力されたファイル)が読み取り専用で格納されます。
学習実行環境で設定される環境変数
- 下記環境変数が KAMONOHASHI によって設定されます。
- 上書き可の環境変数は学習新規登録時に環境変数入力フォームから上書き可能です。
| 環境変数名 | 値 | 上書き可否 | 説明 |
|---|---|---|---|
| LC_ALL | C.UTF-8 | 不可 | システムの文字化け回避のため設定される |
| LANG | C.UTF-8 | 不可 | システムの文字化け回避のため設定される |
| HTTP_PROXY | <デプロイ環境ごと> | 可 | プロキシ設定。システム管理者が指定したデフォルト値が設定される |
| HTTPS_PROXY | <デプロイ環境ごと> | 可 | プロキシ設定。システム管理者が指定したデフォルト値が設定される |
| NO_PROXY | <デプロイ環境ごと> | 可 | プロキシ設定。システム管理者が指定したデフォルト値が設定される |
| http_proxy | <デプロイ環境ごと> | 可 | プロキシ設定。システム管理者が指定したデフォルト値が設定される |
| https_proxy | <デプロイ環境ごと> | 可 | プロキシ設定。システム管理者が指定したデフォルト値が設定される |
| no_proxy | <デプロイ環境ごと> | 可 | プロキシ設定。システム管理者が指定したデフォルト値が設定される |
| COLUMNS | <学習ごと> | 可 | ターミナルの列数設定。システム管理者が指定したデフォルト値が設定される |
| TRAINING_ID | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| DATASET_ID | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| PARENT_ID | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| MODEL_REPOSITORY | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| MODEL_REPOSITORY_TOKEN | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| COMMIT_ID | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| KQI_SERVER | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| KQI_TOKEN | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| KQI_VERSION | <デプロイ環境ごと> | 不可 | KAMONOHASHI のバージョンが設定される |
| ENTRY_POINT | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
| ZIP_FILE_CREATED | <学習ごと> | 不可 | KAMONOHASHI が学習の制御に使用 |
注意事項
- ログファイルの書き出しにはteeコマンドが使われています。 pythonを使用する場合は 「-u」オプションでバッファリングを無効にしないと正しく標準出力結果がログに書き出されないため、注意してください。
推論管理
推論の概要
推論は、上述の学習での結果を用いて推論処理を行うための学習であり、[推論管理]画面で管理されます。 推論の起動は[推論管理]の新規登録ボタンおよび、[学習履歴]画面の推論実行ボタンより可能です。
基本的には学習と同一の仕様であるため、ここでは相違点のみ記載します。
学習との相違点
- マウントする学習で親を指定した場合、指定した学習の出力結果(当該学習の /kqi/output に出力されたファイル)が/kqi/parentに読み取り専用でマウントされます。
- /kqi/output/value.txtに出力された値(1行の数値を想定)が、出力値の列に表示されます。
- コンテナ名は”inference-推論名-推論ID”となります。
- Tensorboardの起動は出来ません。
ノートブック管理
ノートブックの概要
ノートブック機能では、KAMONOHASHI上にJupyterLab環境を提供します。 ノートブックを作成すると、KAMONOHASHIは指定されたCPU、メモリ、GPUリソースを確保しDockerコンテナを起動後、自動的にJupyterLabのインストールを行います。ユーザはこの環境を利用し、Jupyter操作を行うことができます。なおインストールされるJupyterLabのバージョンは1.0.4です。
ノートブックの開始
ノートブックは、[ノートブック管理]を選択後、画面右上のノートブック作成ボタンを選択することで作成できます。 ノートブックの起動に必要な情報は以下の通りです。
| 種類 | 要否 | 説明 |
|---|---|---|
| ノートブック名 | 必須 | ノートブックの名前。 |
| CPU | 必須 | ノートブックが利用するCPUコア数を指定する。 |
| メモリ | 必須 | ノートブックが利用するメモリ量(GB)を指定する。 |
| GPU | 必須 | ノートブックが利用するGPU枚数を指定する。 |
| 起動期間設定 | 必須 | ノートブックの起動期間を設定するかどうかを指定する。テナント設定で無期限実行が許可されている場合のみ設定可能。OFFにすると無期限の実行、ONにすると起動期間を設定しての実行となる。 |
| 起動期間 | 必須 | ノートブックの起動期間(h)を指定する。立ち上げたノートブックは、起動期間終了後に自動で終了する。 |
| インストールするJupyterLabのバージョン | 任意 | コンテナ起動時にインストールされるJupyterLabのバージョンを記入する。コンテナにJupyterLabがインストール済みの場合は、ここで指定したJupyterLabのインストールはスキップされる |
| コンテナイメージ | 任意 | 利用するDockerレジストリ、コンテナ、タグを指定する。未指定の場合は、デフォルト値としてDocker Hubに公開されているkamonohashi/jupyterlab:tensorflow-2.2.0 が利用される。 |
| モデル | 任意 | ソースコードを格納しているGitサーバ、リポジトリ、ブランチ、コミットIDを指定する。コミットIDを指定した場合はブランチの入力値は無視される。コミットIDが未指定の場合はブランチのHEADが選択される。 |
| マウントする学習 | 任意 | ノートブックコンテナにマウントする学習結果を指定する。指定した学習結果が/kqi/parentにマウントされる。 |
| マウントする推論 | 任意 | ノートブックコンテナにマウントする推論結果を指定する。指定した推論結果が/kqi/inferenceにマウントされる。 |
| データセット | 任意 | 利用するデータセットを指定する。ノートブックで利用したデータセットについては、利用後の変更も可能です。 |
| データセット作成方法 | 任意 | コンテナ内へのデータセットの作成方式を指定する。設定による動作の違いはノートブックの動作の流れの項目に記載。 |
| 起動時実行コマンド | 任意 | ノートブック起動時に実行するコマンドを指定する。 |
| 環境変数 | 任意 | ノートブックに渡す環境変数を指定する。環境変数はコンテナ内の環境変数へ追加設定される。 |
| パーティション | 任意 | KAMONOHASHI に設定されているパーティションを設定する。例えばGPUの型番などはここから指定する。 |
| メモ | 任意 | ノートブックに付与する任意のメモ。 |
必要な情報を入力後、実行ボタンを押下することでJupyterLabがインストールされたコンテナが起動します(初回起動時は、ノードにコンテナイメージをダウンロードする必要があるため、実行までに時間がかかります)。
なお利用するDockerイメージには、python3およびpip3がインストールされている必要があります。 Docker Hubで提供されている下記Dockerイメージについては、動作確認を行っています。
- tensorflow/tensorflow:1.15.2-gpu
- pytorch/pytorch:1.1.0-cuda10.0-cudnn7.5-devel
ノートブックへのアクセス
起動後、ステータスがRunningとなったノートブックに対しては、画面上の”ノートブックを開く”を押下することでアクセス可能です。
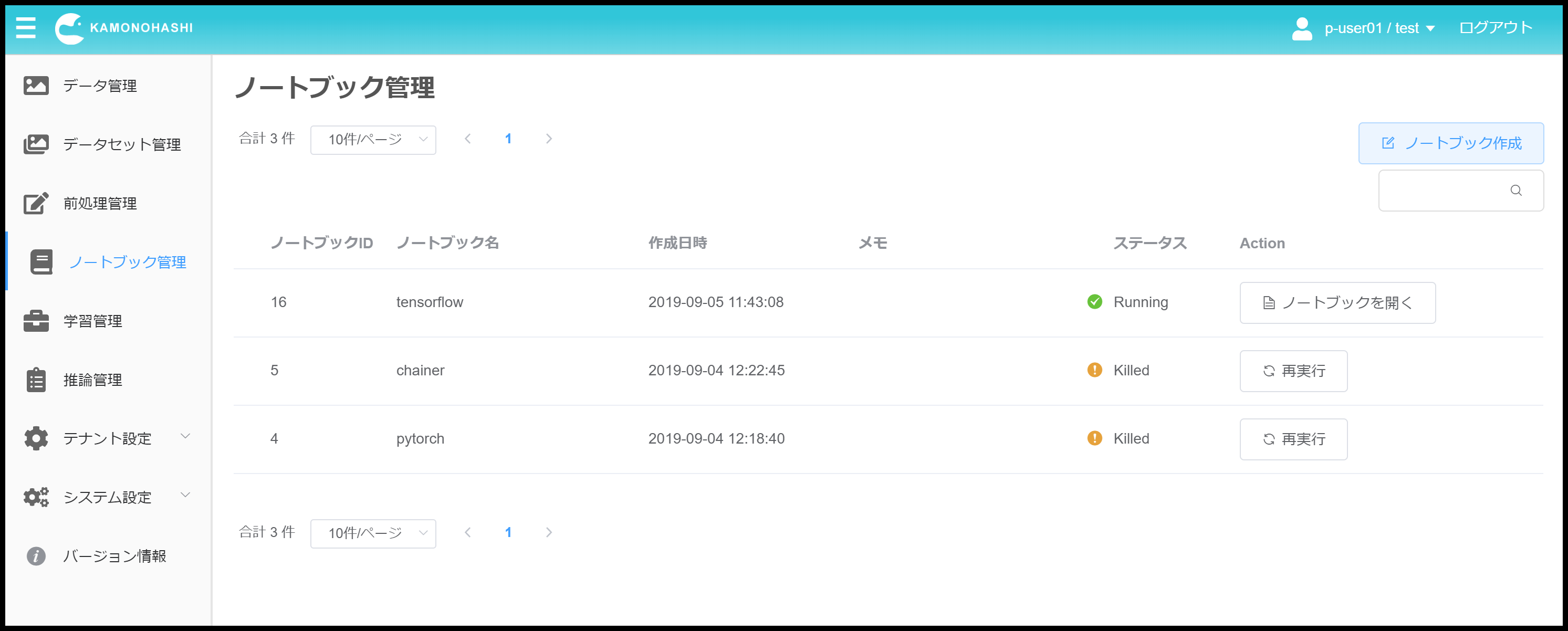
アクセスした際にトークン入力画面が表示される場合は、しばらく待った後に再度アクセスしていただくようお願いします。
ホームディレクトリは/kqi/outputであり、起動後の状態でファイル/ディレクトリ作成すると、ノートブック終了・再起動後もその内容が保持されます。
起動後作成されるディレクトリは下記となっており、それぞれの用途で利用できます。
これらのディレクトリ内作成したファイルは保持されないので注意してください。
| パス | 内容 | 説明 |
|---|---|---|
| /input/ | 入力ファイル | /kqi/inputへのシンボリックリンクであり、指定したデータセットが作成されるディレクトリ |
| /git/ | モデル | /kqi/gitへのシンボリックリンクであり、指定したgitリポジトリがcloneされるディレクトリ |
| /parent/ | モデル | /kqi/parentへのシンボリックリンクであり、マウントする学習で指定したジョブの学習結果がマウントされるディレクトリ |
| /inference/ | モデル | /kqi/inferenceへのシンボリックリンクであり、マウントする推論で指定したジョブの学習結果がマウントされるディレクトリ |
ノートブックの終了
ノートブックコンテナは、指定した生存期間が経過後、自動で終了します。
また詳細画面の”ジョブ停止”を押下することでも終了します。
終了の際には、/kqi/output以外のデータは削除されるため注意してください。
ノートブックの再実行
一度作成したノートブックは、再実行ボタンを押下することで、同じ条件でのコンテナ立ち上げが可能です。/kqi/outputには、以前保存したデータが維持された状態です。
また利用するデータセットに対して変更を加えた際は、その内容が/kqi/inputに反映された状態で、再起動が行われます。
ノートブックの動作の流れ
ノートブックの実行フローは以下のようになっています。
- クラスタからリソースを確保する
- リソース上にコンテナがデプロイされる
- データセットが指定されていれば、データセットを
/kqi/inputに作成する- データセット作成方式でシンボリックリンクを選択した場合は、/kqi/data にマウントした各データに対するシンボリックリンクが作成されます。
- データセット作成方式でローカルコピーを選択した場合は、/kqi/data にマウントした各データのコピーが作成されます。
- ※データセットの作成時間はシンボリックリンク作成の方が短いですが、ノートブック中で頻繁にデータの読み込みが発生する場合はローカルコピーを用いた方が実行時間は短くなります。
- モデルが指定されていれば、モデルを
/kqi/git/に git clone する - 結果保存用ディレクトリ
/kqi/outputを作成する - コンテナにJupyterLabをインストールする
- JupyterLabへのアクセスリンクを画面上に表示する
- 生存期間終了後、コンテナが停止しリソースが開放される